|
Страница 5 из 5 Применим этот алгоритм к сети, показанной на рис. 14.9, я, на примере получения ответа на запрос Ρ (Rain | Sprinkler=true, WetGrass=true). Этот процесс происходит следующим образом: вначале вес w устанавливается равным 1,0, затем вырабатывается событие, как описано ниже. 1. Выборка из распределения ; предположим, что она возвращает значение true. ; предположим, что она возвращает значение true. 2. Sprinkler— переменная доказательства со значением true. Поэтому мы устанавливаем: 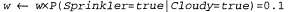
3. Выборка из распределения ; предположим, что она возвращает значение true. ; предположим, что она возвращает значение true. 4. WetGrass — переменная доказательства со значением true. Поэтому мы устанавливаем: 
Теперь алгоритм Weighted-Sample возвращает событие [true, true, true, true] с весом 0,099, и данные об этом событии подытоживаются с учетом условия Rain= true. Этот вес является низким потому, что событие описывает пасмурный день, в который вероятность применения опрыскивателя является весьма небольшой. Чтобы понять, как работает алгоритм оценки веса с учетом правдоподобия, начнем с изучения сформированного с помощью выборок распределения для функции Weighted-Sample. Напомним, что переменные свидетельства Ε зафиксированы со значениями е. Обозначим все прочие переменные как Ζ, иными словами, для функции Weighted-Sample. Напомним, что переменные свидетельства Ε зафиксированы со значениями е. Обозначим все прочие переменные как Ζ, иными словами,  . В алгоритме выборки для каждой переменной из z если даны ее родительские значения, формируются следующим образом: . В алгоритме выборки для каждой переменной из z если даны ее родительские значения, формируются следующим образом:  (14.6) (14.6)
Обратите внимание на то, что в число переменных Parents (zi) могут входить и скрытые переменные, и переменные свидетельства. В отличие от априорного распределения Ρ (z), в распределении некоторое внимание уделено свидетельству: на значения сформированных выборок для каждой переменной zi, кроме других предков Ζi, оказывает влияние само свидетельство. С другой стороны, в распределении некоторое внимание уделено свидетельству: на значения сформированных выборок для каждой переменной zi, кроме других предков Ζi, оказывает влияние само свидетельство. С другой стороны, в распределении свидетельству уделяется меньше внимания, чем в истинном апостериорном распределении Ρ (z | е), поскольку в значениях сформированных выборок для каждой переменной zi игнорируются свидетельства, относящиеся к переменным, которые не являются предками zi. свидетельству уделяется меньше внимания, чем в истинном апостериорном распределении Ρ (z | е), поскольку в значениях сформированных выборок для каждой переменной zi игнорируются свидетельства, относящиеся к переменным, которые не являются предками zi. Весовое значение правдоподобия w представляет собой разность между фактическим и желаемым распределениями вероятностей сформированных выборок. Такой вес для данной конкретной выборки х, состоящий из значений ζ и е, является произведением значений правдоподобия каждой переменной свидетельства, если даны ее родительские переменные (причем некоторые или все эти переменные могут находиться среди переменных zi):  (14.7) (14.7)
Умножая уравнения 14.6 и 14.7, можно определить, что соотношение для взвешенной вероятности выборки имеет следующую особенно удобную форму, поскольку эти два произведения охватывают все переменные, заданные в сети:  (14.8) (14.8)
Это позволяет использовать для вычисления совместной вероятности уравнение 14.1. Теперь можно легко показать, что оценки весов, полученные с учетом правдоподобия, являются согласованными. Для любого конкретного значения χ переменной X оценка апостериорной вероятности может быть рассчитана следующим образом: 

Поэтому алгоритм оценки веса с учетом правдоподобия возвращает согласованные оценки. Поскольку в алгоритме оценки веса с учетом правдоподобия используются все сформированные выборки, он может оказаться гораздо более эффективным по сравнению с алгоритмом формирования выборок с исключением. Тем не менее его недостатком является снижение производительности по мере увеличения количества переменных свидетельства. Это связано с тем, что в таком случае большинство выборок имеет очень низкие веса, поэтому в составе взвешенной оценки доминирует крошечная доля выборок, которые согласуются со свидетельством с правдоподобием, большим бесконечно малого. Эта проблема усугубляется, если переменные свидетельства расположены на последних местах в упорядочении переменных, поскольку в таком случае процесс формирования выборок представляет собой процесс моделирования, имеющий мало сходства с реальностью и имитируемый с помощью свидетельства.
<< В начало < Предыдущая 1 2 3 4 5 Следующая > В конец >>
|