|
Страница 1 из 3 Неконтролируемой кластеризацией называется задача выделения многочисленных категорий в коллекции объектов. Эта проблема — неконтролируемая, поскольку категориям не назначены метки. Например, предположим, что регистрируются спектры сотен тысяч звезд; звезды подразделяются на типы, которые можно определить по спектру, а если так оно и есть, то сколько таких типов и каковы их характеристики? Мы все знакомы с терминами наподобие "красный гигант" и "белый карлик", но звезды не носят эти надписи на своих шляпах, поэтому астрономы должны выполнять неконтролируемую кластеризацию для выявления их категорий. К другим примерам относится выявление видов, родов, отрядов и других категорий в таксономии живых организмов, установленной Линнеем, а также создание естественных разновидностей для распределения по категориям обычных объектов (см. главу 10). Неконтролируемая кластеризация начинается с данных. На рис. 20.8, а показано 500 точек данных, каждая из которых задает значения двух непрерывных атрибутов. Точки данных могут соответствовать звездам, а атрибуты — интенсивностям спектра на двух определенных частотах. Затем необходимо понять, какого рода распределение вероятностей могло быть сформировано этими данными. Сама возможность кластеризации равносильна предположению, что данные сформированы с помощью смешанного распределения Р. Такое распределение имеет к компонентов, каждый из которых представляет собой отдельное распределение. Точка данных формируется путем первоначального выбора компонента, а затем формирования выборки из этого компонента. Допустим, что этот компонент определяет случайная переменная С со значениями 1,..., к; в таком случае смешанное распределение задается следующим выражением:  где χ относится к значениям атрибутов для точки данных. В случае непрерывных данных естественным вариантом выбора для распределений компонентов является многомерное гауссово распределение, что приводит к созданию семейства распределений, представляющего собой так называемое смешанное гауссово распределение. Параметрами смешанного гауссова распределения являются (вес каждого компонента), (вес каждого компонента), (математическое ожидание каждого компонента) и (математическое ожидание каждого компонента) и (ковариация каждого компонента). На рис. 20.8, б показано смешанное гауссово распределение, состоящее из трех распределений; фактически это смешанное распределение было источником данных, приведенных на рис. 20.8, а. (ковариация каждого компонента). На рис. 20.8, б показано смешанное гауссово распределение, состоящее из трех распределений; фактически это смешанное распределение было источником данных, приведенных на рис. 20.8, а. 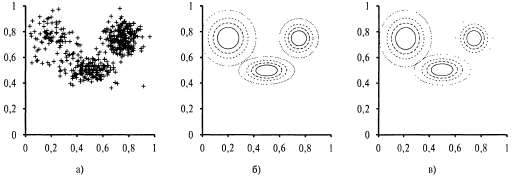 Рис. 20.8. Смешанное гауссово распределение: 500 двухмерных точек данных, показывающих наличие трех кластеров (а); модель смешанного гауссова распределения с тремя компонентами; веса компонентов (слева направо) равны 0.2, 0.3 и 0.5. Данные, приведенные на рис. 20.8, а, были сформированы с помощью этой модели (б); модель, реконструированная из данных, приведенных на рис. 20.8, г., с помощью алгоритма ЕМ (в)
<< В начало < Предыдущая 1 2 3 Следующая > В конец >>
|