|
Страница 4 из 4 Уравнение 17.12 можно рассматривать как определение модели перехода для пространства доверительных состояний. Мы можем также определить функцию вознаграждения для доверительных состояний (т.е. ожидаемое вознаграждение, относящееся к фактическим состояниям, в которых может находиться агент) следующим образом: 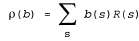
Итак, создается впечатление, что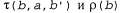 совместно определяют наблюдаемую задачу MDP в пространстве доверительных состояний. Кроме того, можно показать, что оптимальная стратегия для этой задачи MDP, π* (b), является также оптимальной стратегией для оригинальной задачи POMDP. Другими словами, решение любой задачи POM DP в пространстве физических состояний можно свести к решению задачи MDP в соответствующем пространстве доверительных состояний. Этот факт, возможно, станет менее удивительным, если мы вспомним, что доверительное состояние по определению всегда является наблюдаемым для агента. совместно определяют наблюдаемую задачу MDP в пространстве доверительных состояний. Кроме того, можно показать, что оптимальная стратегия для этой задачи MDP, π* (b), является также оптимальной стратегией для оригинальной задачи POMDP. Другими словами, решение любой задачи POM DP в пространстве физических состояний можно свести к решению задачи MDP в соответствующем пространстве доверительных состояний. Этот факт, возможно, станет менее удивительным, если мы вспомним, что доверительное состояние по определению всегда является наблюдаемым для агента. Но необходимо отметить следующее: хотя мы свели задачу POMDP к задаче MDP, полученная задача MDP имеет непрерывное (а иногда многомерное, с большим количеством размерностей) пространство состояний. Для решения подобных задач MDP нельзя непосредственно применить ни один из алгоритмов MDP, описанных в разделах 17.2 и 17.3. Но, как оказалось, существует возможность разработать версии алгоритмов итерации по значениям и итерации по стратегиям, которые могут применяться для решения задач Μ DP с непрерывными состояниями. Основная идея состоит в том, что стратегия π (b) может быть представлена как множество областей пространства доверительных состояний, каждая из которых связана с конкретным оптимальным действием4. Функция стоимости связывает с каждой из областей отдельную линейную функцию от b. На каждом этапе итерации по значениям или по стратегиям уточняются границы областей и могут вводиться новые области. Подробное описание соответствующих алгоритмов выходит за рамки данной книги, но мы сообщаем решение для мира 4x3 без датчиков. Оптимальная стратегия состоит в следующем: [Left, Up, Up,Right, Up, Up,Right, Up, Up,Right, Up,Right, Up,Right, Up, ...] Этот стратегия представляет собой последовательность, поскольку рассматриваемая задача в пространстве доверительных состояний является детерминированной — в ней нет наблюдений. Воплощенный в этой стратегии "секрет" состоит в том, что нужно предусмотреть для агента однократное движение Left для проверки того, что он не находится в квадрате (4,1), с тем чтобы в дальнейшем было достаточно безопасно продолжать движения Up и Right для достижения выхода +1. Агент достигает выхода +1 в 86,6% попыток и добивается этого гораздо быстрее по сравнению со стратегией, приведенной выше в данном разделе, поэтому его ожидаемая полезность повышается до 0 . 38, что гораздо больше по сравнению с 0 . 08. Для более сложных задач POMDP с непустыми результатами наблюдений приближенный поиск оптимальных стратегий является очень сложным (фактически такие задачи являются PSPACE-трудными, т.е. действительно чрезвычайно трудными). Задачи с несколькими десятками состояний часто оказываются неразрешимыми. В следующем разделе описан другой, приближенный метод решения задач POMDP, основанный на опережающем поиске.
<< В начало < Предыдущая 1 2 3 4 Следующая > В конец >>
|