|
Страница 3 из 4 Основная идея, необходимая для понимания сути задач POMDP, состоит в следующем: оптимальное действие зависит только от текущего доверительного состояния агента. Это означает, что оптимальную стратегию можно описать, отобразив стратегию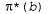 с доверительных состояний на действия. Она не зависит от фактического состояния, в котором находится агент. Это— очень благоприятная особенность, поскольку агент не знает своего фактического состояния; все, что он знает, — это лишь его доверительное состояние. Поэтому цикл принятия решений агентом POMDP состоит в следующем. с доверительных состояний на действия. Она не зависит от фактического состояния, в котором находится агент. Это— очень благоприятная особенность, поскольку агент не знает своего фактического состояния; все, что он знает, — это лишь его доверительное состояние. Поэтому цикл принятия решений агентом POMDP состоит в следующем. 1. С учетом текущего доверительного состояния b выполнить действие  2. Получить результаты наблюдения о. 3. Установить текущее доверительное состояние равным Forward (b, а, о) и повторить ту же процедуру. Теперь мы можем рассматривать задачи POMDP как требующие поиска в пространстве доверительных состояний, во многом аналогично тем методам, которые применялись для решения задач в отсутствие датчиков и задач в условиях непредвиденных ситуаций, описанных в главе 3. Основное различие состоит в том, что пространство доверительных состояний POMDP является непрерывным, поскольку доверительное состояние POMDP — это распределение вероятностей. Например, доверительное состояние для мира 4x3 представляет собой точку в 11-мерном непрерывном пространстве. Любое действие изменяет не только физическое состояние, но и доверительное состояние, поэтому оценивается согласно информации, полученной агентом в качестве результата. Таким образом, задачи POMDP должны включать стоимость информации в качестве одного из компонентов задачи принятия решений (см. раздел 16.6). Рассмотрим более внимательно результаты действий. В частности, рассчитаем вероятность того, что агент, находящийся в доверительном состоянии b, достигнет доверительного состояния b' после выполнения действия а. Итак, если известно действие и последующее наблюдение, то уравнение 17.11 должно обеспечить получение детерминированного обновления доверительного состояния, иными словами, b' =Forward(b,а,о). Безусловно, результаты последующего наблюдения еще не известны, поэтому агент может перейти в одно из нескольких возможных доверительных состояний b', в зависимости от того наблюдения, которое последует за данным действием. Вероятность получения результатов наблюдения о, при условии, что действие а было выполнено в доверительном состоянии b, определяется путем суммирования по всем фактическим состояниям s', которых может достичь агент: 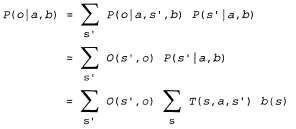
Обозначим вероятность достижения состояния b' из b, если дано действие а, как 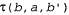 . В таком случае справедливо следующее соотношение: . В таком случае справедливо следующее соотношение:  (17.12) (17.12)
где равно 1, если b' =Forward(b, а, о), и 0 — в противном случае. равно 1, если b' =Forward(b, а, о), и 0 — в противном случае.
|