|
Адаптивное динамическое программирование |
|
Страница 1 из 2 Для того чтобы можно было воспользоваться преимуществами наличия информации об ограничениях между состояниями, агент должен определить с помощью обучения, как связаны эти состояния. Агент, действующий по принципу адаптивного динамического программирования (или сокращенно ADP— Adaptive Dynamic Programming), функционирует путем определения с помощью обучения модели перехода в этой среде по мере выполнения своих действий и находит решение в соответствующем марковском процессе принятия решений, используя метод динамического программирования. Для пассивного обучающегося агента такой подход означает, что он должен подставлять полученную с помощью обучения модель перехода 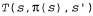 и наблюдаемые вознаграждения R(s) в уравнения Беллмана 21.2 для вычисления полезностей состояний. Как было отмечено при обсуждении в главе 17 принципа итерации по стратегиям, эти уравнения являются линейными (для них не требуется максимизация), поэтому они могут быть решены с помощью любого пакета линейной алгебры. Еще один вариант состоит в том, что может быть принят подход, основанный на принципе модифицированной итерации по стратегиям , в котором используется упрощенный процесс итерации по значениям для обновления оценок полезностей после каждого изменения в модели, определяемой с помощью обучения. Поскольку эта модель после каждого наблюдения подвергается только незначительным изменениям, в процессе итерации по значениям в качестве начальных значений могут использоваться предыдущие оценки полезностей, а сами вычисления с помощью этого метода должны сходиться очень быстро. и наблюдаемые вознаграждения R(s) в уравнения Беллмана 21.2 для вычисления полезностей состояний. Как было отмечено при обсуждении в главе 17 принципа итерации по стратегиям, эти уравнения являются линейными (для них не требуется максимизация), поэтому они могут быть решены с помощью любого пакета линейной алгебры. Еще один вариант состоит в том, что может быть принят подход, основанный на принципе модифицированной итерации по стратегиям , в котором используется упрощенный процесс итерации по значениям для обновления оценок полезностей после каждого изменения в модели, определяемой с помощью обучения. Поскольку эта модель после каждого наблюдения подвергается только незначительным изменениям, в процессе итерации по значениям в качестве начальных значений могут использоваться предыдущие оценки полезностей, а сами вычисления с помощью этого метода должны сходиться очень быстро.
<< В начало < Предыдущая 1 2 Следующая > В конец >>
|