|
Страница 2 из 2 Сам процесс определения модели с помощью обучения осуществляется просто, поскольку среда полностью наблюдаема. Это означает, что данная задача обучения представляет собой задачу контролируемого обучения, в которой входными данными являются пары "состояние—действие", а выходными— результирующие состояния. В простейшем случае модель перехода можно представить как таблицу вероятностей и следить за тем, насколько часто возникает каждый результат действия1, оценивая вероятность перехода T(s, a, s' ) по данным о частоте, с которой достигается состояние s' при выполнении действия а в состоянии s. Например, в трех трассировках попыток, приведенных на с. 1013, действие Right в состоянии (1,3) выполняется три раза, и двумя из трех результирующих состояний становится состояние (2,3), поэтому вероятность перехода Τ ( (1,3) , Right, (2,3) ) оценивается как 2/3. Полная программа агента для пассивного агента ADP приведена в листинге 21.1. Производительность этой программы в мире 4x3 показана на рис. 21.2. Судя по тому, насколько быстро улучшаются полученные им оценки значений, агент ADP действует настолько успешно, насколько это возможно, учитывая его способность определять с помощью обучения модель перехода. В этом смысле данный проект агента может служить эталоном, с которым можно будет сравнивать производительность других алгоритмов обучения с подкреплением. Тем не менее в больших пространствах состояний такой подход становится не вполне осуществимым. Например, в нардах для его использования потребуется решить приблизительно 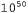 уравнений с уравнений с неизвестными. неизвестными. Листинг 21.1. Алгоритм агента для пассивного обучения с подкреплением, основанный на адаптивном динамическом программировании. Для упрощения кода было принято предположение, что каждый результат восприятия можно разделить на информацию о состоянии и сигнал о вознаграждении 
<< В начало < Предыдущая 1 2 Следующая > В конец >>
|