|
Страница 2 из 4 planning purely diagnostic expert systems are very similar computational approach would be represented compactly using tic tac toe a predicate Вообще говоря, в модели n-словных сочетаний учитываются предыдущие n-1 слов и присваивается вероятность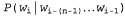 . Приведенная ниже случайная последовательность сформирована с помощью модели трехсловных сочетаний по оригиналу данной книги. . Приведенная ниже случайная последовательность сформирована с помощью модели трехсловных сочетаний по оригиналу данной книги. planning and scheduling are integrated the success of naive bayes model is just a possible prior source by that time Даже эти небольшие примеры позволяют понять, что модель трехсловных сочетаний превосходит модель двухсловных сочетаний (а последняя превосходит модель однословных сочетаний) как с точки зрения качества приближенного представления текста на английском языке, так и с точки зрения успешной аппроксимации изложения темы в книге по искусственному интеллекту. Согласуются и сами модели: в модели трехсловных сочетаний строке, сформированной случайным образом, присваивается вероятность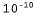 , в модели двухсловных сочетаний — вероятность , в модели двухсловных сочетаний — вероятность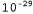 , а в модели однословных сочетаний — вероятность , а в модели однословных сочетаний — вероятность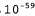 Но оригинал настоящей книги содержит всего лишь полмиллиона слов, поэтому в нем отсутствует достаточный объем данных для выработки качественной модели двухсловных сочетаний, не говоря уже о модели трехсловных сочетаний. Весь словарь оригинала данной книги включает примерно 15 тысяч различных слов, поэтому модель двухсловных сочетаний включает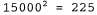 миллионов пар слов. Безусловно, что вероятность появления по меньшей мере 99,8% этих пар будет равна нулю, но сама модель не должна указывать на то, что появление любой из этих пар в тексте невозможно. Поэтому требуется определенный способ сглаживания нулевых результатов фактического подсчета количества пар. Простейший способ выполнения этой задачи состоит в использовании так называемого способа сглаживания с добавлением единицы: к результатам подсчета количества всех возможных двухсловных сочетаний добавляется единица. Поэтому, если количество слов в текстовой совокупности равно N, а количество возможных двухсловных сочетаний равно в, то каждому двухсловному сочетанию с фактическим количеством с присваивается оценка вероятности (с+1) / (N+B). Такой метод позволяет устранить проблему п-словных сочетаний с нулевой вероятностью, но само предположение, что все результаты подсчета количества должны быть увеличены точно на единицу, является сомнительным и может привести к получению некачественных оценок. миллионов пар слов. Безусловно, что вероятность появления по меньшей мере 99,8% этих пар будет равна нулю, но сама модель не должна указывать на то, что появление любой из этих пар в тексте невозможно. Поэтому требуется определенный способ сглаживания нулевых результатов фактического подсчета количества пар. Простейший способ выполнения этой задачи состоит в использовании так называемого способа сглаживания с добавлением единицы: к результатам подсчета количества всех возможных двухсловных сочетаний добавляется единица. Поэтому, если количество слов в текстовой совокупности равно N, а количество возможных двухсловных сочетаний равно в, то каждому двухсловному сочетанию с фактическим количеством с присваивается оценка вероятности (с+1) / (N+B). Такой метод позволяет устранить проблему п-словных сочетаний с нулевой вероятностью, но само предположение, что все результаты подсчета количества должны быть увеличены точно на единицу, является сомнительным и может привести к получению некачественных оценок.
|