|
Страница 2 из 3 Классификация — это задача контролируемого обучения, поэтому для ее решения может применяться любой из методов, описанных в главе 18. Один из широко используемых подходов состоит в формировании деревьев решений. После подготовки обучающего множества документов, обозначенных правильными категориями, может быть сформировано единственное дерево решений, листьям которого поставлены в соответствие документы, принадлежащие к той или иной категории. Такой подход полностью себя оправдывает, если имеется лишь несколько категорий, но при наличии более крупных множеств категорий приходится формировать по одному дереву решений для каждой категории, притом что листья этого дерева обозначают документ как принадлежащий или не принадлежащий к данной категории. Обычно характеристиками, проверяемыми в каждом узле, являются отдельные слова. Например, в одном из узлов дерева решений для категории "Sports" может быть предусмотрена проверка наличия слова "basketball". Для классификации текстов были опробованы такие средства, как усиленные деревья решений, наивные байесовские модели и машины поддерживающих векторов; во многих случаях точность при использовании булевой классификации находилась в пределах 90-98%. Кластеризация относится к типу задач неконтролируемого обучения. В разделе 20.3 было показано, как может использоваться алгоритм ЕМ для улучшения начальной оценки кластеризации на основе сочетания гауссовых моделей. Задача кластеризации документов является более сложной, поскольку неизвестно, было ли выполнено формирование данных с помощью правильной гауссовой модели, а также в связи с тем, что приходится действовать в условиях пространства поиска, имеющего намного больше размерностей. Для решения этой задачи был разработан целый ряд подходов. В методе агломеративной кластеризации создается дерево кластеров путем выполнения полной обработки совокупности вплоть до отдельных документов. Отсечение ветвей этого дерева для получения меньшего количества категорий может быть выполнено на любом уровне, но такая операция рассматривается как выходящая за рамки самого алгоритма. На первом этапе каждый документ рассматривается как отдельный кластер. После этого отыскиваются два кластера, наиболее близкие друг к другу согласно определенному критерию расстояния, и эти два кластера сливаются в один. Такой процесс повторяется до тех пор, пока не остается только один кластер. Критерием расстояния между двумя документами является некоторый критерий, измеряющий совпадение слов в этих документах. Например, документ может быть представлен как вектор количества слов, а само расстояние определено как евклидово расстояние между двумя векторами. Критерием расстояния между двумя кластерами может служить расстояние до середины кластера или может учитываться среднее расстояние между элементами кластеров. Метод агломеративной кластеризации требует затрат времени, пропорциональных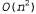 , где η — количество документов. , где η — количество документов.
|