|
Постановка знаменитой задачи поиска равновесия системы тележка—шест, известной также под названием задачи обратного маятника, показана на рис. 21.6. Задача состоит в том, чтобы обеспечить управление положением тележки в направлении оси χ таким образом, чтобы шест стоял примерно вертикально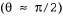 а сама тележка оставалась в пределах длины пути, как показано на этом рисунке. Такой с виду простой задаче посвящено свыше двух тысяч статей по обучению с подкреплением и теории управления. Задача с тележкой и шестам отличается от описанных выше задач тем, что переменные состояния а сама тележка оставалась в пределах длины пути, как показано на этом рисунке. Такой с виду простой задаче посвящено свыше двух тысяч статей по обучению с подкреплением и теории управления. Задача с тележкой и шестам отличается от описанных выше задач тем, что переменные состояния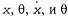 являются непрерывными. С другой стороны, действия обычно остаются дискретными: таковыми являются рывки тележки влево или вправо в так называемом режиме релейного управления. являются непрерывными. С другой стороны, действия обычно остаются дискретными: таковыми являются рывки тележки влево или вправо в так называемом режиме релейного управления. 
Рис. 21.6. Постановка задачи уравновешивания длинного шеста, установленного на движущейся тележке. Контроллер, измеряющий значения x, Θ, χ и Θ, рывками двигает тележку влево или вправо Одна из первых работ по обучению механической системы решению этой задачи была выполнена Мичи и Чамберсом [1046]. Разработанный ими алгоритм Boxes оказался способным поддерживать равновесие шеста больше одного часа после всего лишь 30 пробных попыток. Более того, в отличие от многих разработанных в дальнейшем систем, алгоритм Boxes был реализован с помощью реальной тележки и шеста, а не эмулятора. На первых порах в этом алгоритме применялась дискретизация четырехмерного пространства состояний с разбивкой на гиперкубы, называемые разработчиками boxes', отсюда произошло название алгоритма. После ввода алгоритма в действие выполнялись учебные попытки, продолжавшиеся до тех пор, пока не падал шест или тележка не достигала конца пути. Отрицательное подкрепление связывалось с заключительным действием в конечном гиперкубе, а затем распространялось в обратном направлении через всю последовательность действий. В дальнейшем было обнаружено, что применяемый способ дискретизации становится причиной возникновения некоторых проблем, когда вся эта экспериментальная установка инициализировалась в позиции, отличной от той, которая применялась при обучении (что свидетельствовало о недостаточно качественном обобщении). Лучшего обобщения и более быстрого обучения можно добиться, используя алгоритм, который адаптивно фрагментирует пространство состояний согласно наблюдаемому изменению в вознаграждении. В наши дни считается тривиальной задача уравновешивания трех обратных маятников, что значительно превосходит возможности большинства людей.
|