|
Страница 3 из 4 Таблица 15.2. Часть таблицы частот однословных и двухсловных сочетаний для слов в оригинале данной книги. В ней наиболее часто применяемым отдельным словом является "the", и общее количество случаев, в которых встречается это слово, равно 33 508 (из общего количества слов, равного 513 893). Наиболее часто встречающимся двухсловным сочетанием является "of the", с общим количеством 3833. Некоторые частоты оказались больше ожидаемого (например, 4 раза встречается невероятное сочетание "on is"), поскольку при подсчете количества двухсловных сочетаний игнорируется знаки препинания, одно предложение может оканчиваться словом "on", а другое — начинаться со слова "is" 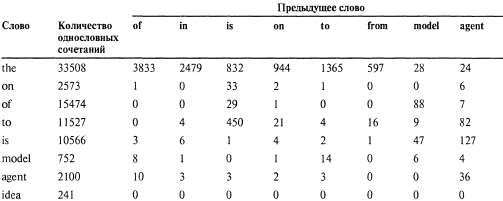 Теперь рассмотрим, как скомбинировать языковую модель со словесными моделями, чтобы иметь возможность правильно обрабатывать последовательности слов. Для упрощения предполагается, что будет использоваться двухсловная языковая модель. С помощью такой модели можно скомбинировать все словесные модели (которые, в свою очередь, состоят из моделей произношения и моделей фонем) в одну большую модель НММ. Состоянием в однословной модели НММ является фрейм с меткой, представляющей собой текущую фонему и состояние фонемы (например,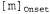 ); любое состояние в модели НММ непрерывной речи снабжается также меткой в виде слова, как, например, ); любое состояние в модели НММ непрерывной речи снабжается также меткой в виде слова, как, например,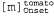 . Если каждое слово в своей модели произношения имеет в среднем ρ фонем с тремя состояниями, а общее количество слов равно w, то модель НММ непрерывной речи имеет 3pW состояний. Переходы могут происходить между состояниями фонем в пределах данной конкретной фонемы, между фонемами данного конкретного слова, а также между конечным состоянием одного слова и начальным состоянием другого. Переходы между словами происходят с вероятностями, заданными с помощью двухсловной модели. . Если каждое слово в своей модели произношения имеет в среднем ρ фонем с тремя состояниями, а общее количество слов равно w, то модель НММ непрерывной речи имеет 3pW состояний. Переходы могут происходить между состояниями фонем в пределах данной конкретной фонемы, между фонемами данного конкретного слова, а также между конечным состоянием одного слова и начальным состоянием другого. Переходы между словами происходят с вероятностями, заданными с помощью двухсловной модели. После составления такой комбинированной модели НММ ее можно использовать для анализа непрерывного речевого сигнала. В частности, для обнаружения наиболее вероятной последовательности состояний может применяться алгоритм Витерби, представленный в виде уравнения 15.9. Затем из этой последовательности состояний можно извлечь последовательность слов, считывая метки слов из состояний. Таким образом, алгоритм Витерби позволяет решить проблему сегментации непрерывной речи на отдельные слова, поскольку в нем (по сути) используется динамическое программирование для одновременного учета не только всех возможных последовательностей слов, но и границ между словами.
|