|
Страница 1 из 4 Последний подход к решению задач обучения с подкреплением, который рассматривается в этой главе, носит название поиска стратегии. В определенных отношениях метод, основанный на поиске стратегии, является самым простым из всех методов, рассматриваемых в данной главе; его идея состоит в том, что необходимо продолжать корректировать стратегию до тех пор, пока связанная с ней производительность увеличивается, а после этого останавливаться. Начнем с анализа самих стратегий. Напомним, что стратегией π называется функция, которая отображает состояния на действия. Нас прежде всего интересуют параметризованные представления π, которые имеют намного меньше параметров по сравнению с количеством состояний в пространстве состояний (как и в предыдущем разделе). Например, можно представить стратегию π в виде коллекции параметризованных Q-функций, по одной для каждого действия, и каждый раз предпринимать действие с наивысшим прогнозируемым значением: 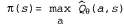 (21.13) (21.13)
Каждая Q-функция может представлять собой линейную функцию от параметров Θ, как показано в уравнении 21.9, или может быть и нелинейной функцией, например, представленной в виде нейронной сети. В таком случае поиск стратегии сводится к корректировке параметров θ в целях улучшения стратегии. Следует отметить, что если стратегия представлена с помощью Q-функций, то поиск стратегии приводит к процессу определения Q-функций с помощью обучения. Этот процесс не следует рассматривать как Q-обунение! При Q-обучении с помощью функциональной аппроксимации алгоритм находит такое значение Θ, что функция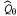 становится "близкой" к функции Q* — оптимальной Q-функции. При поиске стратегии, с другой стороны, отыскивается значение Θ, которое приводит к достижению высокой производительности; найденные значения могут отличаться весьма существенно6. Еще одним примером, четко иллюстрирующим это различие, является случай, в котором становится "близкой" к функции Q* — оптимальной Q-функции. При поиске стратегии, с другой стороны, отыскивается значение Θ, которое приводит к достижению высокой производительности; найденные значения могут отличаться весьма существенно6. Еще одним примером, четко иллюстрирующим это различие, является случай, в котором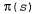 вычисляется, допустим, с помощью опережающего поиска на глубину 10 с приближенной функцией полезности вычисляется, допустим, с помощью опережающего поиска на глубину 10 с приближенной функцией полезности . Значение Θ, позволяющее обеспечить качественное ведение игры, может быть получено задолго до того, как удастся получить приближение . Значение Θ, позволяющее обеспечить качественное ведение игры, может быть получено задолго до того, как удастся получить приближение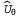 , напоминающее истинную функцию полезности. , напоминающее истинную функцию полезности.
<< В начало < Предыдущая 1 2 3 4 Следующая > В конец >>
|