|
Страница 1 из 2 Выше была кратко описана модель для Ρ ( f| Ε), которая предусматривает применение четырех перечисленных ниже множеств параметров. • Языковая модель.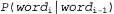 • Модель фертильности.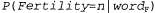 • Модель выбора слова.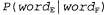 • Модель смещения.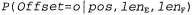 Но даже при использовании скромного словаря, состоящего из 1000 слов, для этой модели требуются миллионы параметров. Очевидно, что необходимо обеспечить определение этих параметров с помощью обучения на основе данных. Предположим, что единственными доступными данными является двуязычная совокупность текстов. Ниже описан способ использования этих данных. • Сегментация на предложения. Единицей перевода является предложение, поэтому нам потребуется разбить совокупность текстов на предложения. Надежным показателем конца предложения является точка, но в таком фрагменте текста, как "Dr. J. R. Smith of Rodeo Dr. arrived.", признаком конца предложения является только последняя точка. Сегментация на предложения может быть выполнена с точностью около 98%. • Оценка языковой модели для французского языка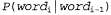 . Рассматривая только французскую половину совокупности текстов, подсчитать частоты пар слов и выполнить выравнивание, чтобы получить оценку . Рассматривая только французскую половину совокупности текстов, подсчитать частоты пар слов и выполнить выравнивание, чтобы получить оценку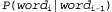 Например, может быть получено значение Ρ ("Eiffel" | "tour") = .02. Например, может быть получено значение Ρ ("Eiffel" | "tour") = .02. • Выравнивание предложений. Для каждого предложения в английской версии определить, какое предложение (предложения) соответствует ему во французской версии. Обычно следующее предложение в английском тексте соответствует следующему предложению во французском тексте в форме согласования "один к одному", но иногда возникают другие варианты: одно предложение на одном из языков может быть разбито на два, что приводит к согласованию "два к одному", или может быть изменен на противоположный порядок следования двух предложений, а это приведет к согласованию "два к двум". Выравнивание предложений ("один к одному", "один к двум" или "два к двум" и т.д.) может быть обеспечено только на основании сравнения длины предложений с точностью в пределах от 90 до 99% с использованием одного из вариантов алгоритма сегментации Витерби (см. листинг 23.1). С применением отметок, общих для обоих языков, таких как числа или имена собственные, а также слов, которые, как известно, имеют в двуязычном словаре однозначный перевод, можно добиться еще лучшего выравнивания.
<< В начало < Предыдущая 1 2 Следующая > В конец >>
|