|
Страница 1 из 2 Теперь, после разработки алгоритма активного агента ADP, рассмотрим, как сконструировать активного агента, обучающегося по методу временной разности. Наиболее очевидным отличием от пассивного варианта является то, что агенту больше не предоставлена заданная стратегия, поэтому для определения с помощью обучения функции полезности U агенту потребуется определить с помощью обучения некоторую модель, чтобы иметь возможность выбрать с учетом значения и некоторое действие, выполнив прогнозирование на один шаг вперед. Задача приобретения модели для агента TD идентична такой же задаче для агента ADP. А что можно сказать о самом правиле обновления TD? Возможно, что следующее утверждение на первый взгляд покажется удивительным, но правило обновления 21.3 остается неизменным. Такая ситуация может показаться странной по следующей причине: предположим, что агент делает шаг, который обычно приводит в приемлемое место назначения, но из-за наличия недетерминированности в самой среде в конечном итоге агент оказывается в катастрофическом состоянии. Правило обновления TD позволяет отнестись к этой ситуации так же серьезно, как если бы полученным итогом был нормальный результат действия, тогда как можно было предположить, что агент не должен слишком сильно об этом беспокоиться, поскольку такой итог возник лишь из-за стечения обстоятельств. Безусловно, такой маловероятный результат в большом множестве обучающих последовательностей может возникать достаточно редко, поэтому можно надеяться, что в долговременной перспективе его последствия получат вес, пропорциональный их вероятности. Еще раз отметим следующее — можно доказать, что алгоритм TD сходится к тем же значениям, что и ADP, по мере того как количество обучающих последовательностей стремится к бесконечности. Есть также альтернативный метод TD, называемый Q-обучением, в котором предусматривается определение с помощью обучения некоторого представления "действие-стоимость" вместо определения полезностей. Для обозначения стоимости выполнения действия а в состоянии s будет использоваться запись Q(a,s). Отметим, что Q-значения непосредственно связаны со значениями полезностей следующим образом: 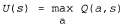 (21.6) (21.6)
На первый взгляд может показаться, что Q-функции представляют собой лишь еще один способ хранения информации о полезностях, но они обладают очень важным свойством: агенту TD, который определяет Q-функцию с помощью обучения, не требуется модель ни для обучения, ни для выбора действия. По этой причине Q-обучение называют безмодельным методом. Как и в случае полезностей, можно записать следующее уравнение для ограничений, которое должно соблюдаться в точке равновесия, когда Q-значения являются правильными: 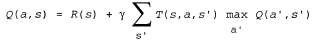 (21.7) (21.7)
<< В начало < Предыдущая 1 2 Следующая > В конец >>
|