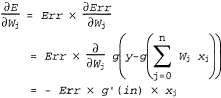|
Страница 3 из 4 Для уменьшения квадратичной ошибки можно применить метод градиентного спуска, вычисляя частичную производную Ε по отношению к каждому весу. При этом может быть получено следующее соотношение: где g' — производная функции активации. В алгоритме градиентного спуска предусмотрено, что если требуется уменьшить Е, то вес обновляется следующим образом:  (20.12) (20.12)
где α — скорость обучения. Интуитивно ясно, что приведенное выше уравнение имеет большой смысл. Если ошибка является положительной, то выход сети слишком мал и поэтому веса увеличиваются при положительных входных данных и уменьшаются при отрицательных входных данных. А если ошибка является отрицательной, то происходит противоположное. является положительной, то выход сети слишком мал и поэтому веса увеличиваются при положительных входных данных и уменьшаются при отрицательных входных данных. А если ошибка является отрицательной, то происходит противоположное. Полный алгоритм приведен в листинге 20.1. Он предусматривает прогон обучающих примеров через сеть каждый раз по одному и небольшую корректировку весов после прогона каждого примера для уменьшения ошибки. Каждый цикл прогона примеров называется эпохой. Эпохи повторяются до тех пор, пока не достигается некоторый критерий останова; как правило, такая ситуация достигается, когда изменения весов становятся очень небольшими. В других методах для всего обучающего набора вычисляется градиент путем сложения всех градиентных вкладов в уравнении 20.12 перед обновлением весов. А в методе стохастического градиента примеры выбираются случайным образом из обучающего набора вместо их циклической обработки. Листинг 20.1. Алгоритм обучения на основе градиентного спуска для персептронов, в котором предполагается использование дифференцируемой функции активации д. Для пороговых персептронов коэффициент дg'(in) из обновления веса исключается. Функция Neural-Net-Hypothesis возвращает гипотезу, которая вычисляет выход сети для любого конкретного примера 

На рис. 20.21 показаны кривые обучения персептрона для двух разных задач. Слева показана кривая для определения в процессе обучения мажоритарной функции с 11 булевыми входами (т.е. функция выводит 1, если на шести или больше входах присутствует 1). Как и следовало ожидать, персептрон определяет эту функцию в процессе обучения очень быстро, поскольку мажоритарная функция является линейно разделимой. С другой стороны, обучающееся устройство, основанное на использовании дерева решений, не добивается существенного прогресса, поскольку мажоритарную функцию очень сложно (хотя и возможно) представить в виде дерева решений. Справа показана задача с рестораном. Решение этой задачи можно легко представить в виде дерева решений, но соответствующая функция не является линейно разделимой. Наилучшая гиперплоскость, разделяющая данные, позволяет правильно классифицировать только 65% примеров. 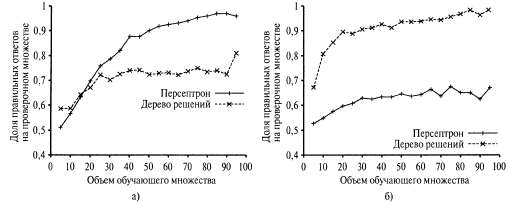 Рис. 20.21. Сравнение производительности персептронов и деревьев решений: персептроны показывают более высокую производительность при определении в процессе обучения мажоритарной функции от И входов (а); деревья решений показывают лучшую производительность при определении в процессе обучении предиката willWait в задаче с рестораном (б)
|