|
Страница 3 из 4  Рис. 18.7. Иллюстрация работы алгоритма усиления. Каждый затененный прямоугольник соответствует некоторому примеру; высота прямоугольника соответствует весу. Галочки и крестики показывают, был ли данный пример классифицирован правильно с помощью текущей гипотезы. Размер дерева решений показывает вес этой гипотезы в окончательном ансамбле Листинг 18.2. Один из вариантов метода усиления для обучения ансамбля, представленный в виде алгоритма AdaBoost. Этот алгоритм вырабатывает гипотезу, последовательно корректируя веса обучающих примеров. Функция Weighted-Majority вырабатывает гипотезу, которая возвращает выходное значение с наивысшими результатами голосования из числа гипотез, относящихся к вектору h, где результаты голосования взвешиваются с помощью вектора z 

Рассмотрим, насколько хорошо метод усиления действует применительно к данным о ресторане. Выберем в качестве первоначального пространства гипотез класс одноузловых деревьев решений, представляющих собой деревья решений только с одной проверкой, в корневом узле. Нижняя кривая, приведенная на рис. 18.8, я, показывает, что неусиленные одноузловые деревья решений не очень эффективно действуют применительно к этому набору данных, достигая производительности предсказания, составляющей только 81% в расчете на 100 обучающих примеров. А после применения метода усиления (при м=5) производительность становится выше и достигает 93% после обработки 100 примеров. 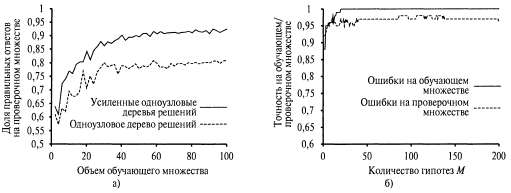 Рис. 18.8. Анализ производительности алгоритмов: график, показывающий, как изменяется производительность усиленных одноузловых деревьев решений при М=5 по сравнению с неусиленными одноузловыми деревьями решений на примере данных о ресторане (а); доля правильных ответов, полученных на обучающем множестве и проверочном множестве, как функция от Μ (от количества гипотез в ансамбле) (б). Обратите внимание на то, что точность распознавания примеров из проверочного множества немного повышается даже после того, как точность распознавания примеров из обучающего множества достигает 1, т.е. после того, как ансамбль гипотез полностью согласуется с данными
|