|
Страница 2 из 5 Функциональная аппроксимация может дать возможность представить функции полезности для очень больших пространств состояний, но ее основное преимущество состоит не в этом. Сжатие, достигнутое с помощью аппроксиматора функции, позволяет обучающемуся агенту делать обобщения, распространяющиеся с тех состояний, которые он уже посетил, на состояния, которые он еще не посетил. Это означает, что наиболее важным аспектом функциональной аппроксимации является не то, что она требует меньше пространства, а то, что она обеспечивает индуктивное обобщение по входным состояниям. Чтобы дать читателю представление о возможностях этого подхода, укажем, что путем исследования только одного состояния из каждой группы по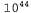 возможных состояний в игре в нарды можно определить с помощью обучения функцию полезности, позволяющую программе играть не хуже любого игрока-человека [1499]. возможных состояний в игре в нарды можно определить с помощью обучения функцию полезности, позволяющую программе играть не хуже любого игрока-человека [1499]. Оборотной стороной этого подхода, безусловно, является то, что с ним связана такая проблема: невозможность найти в выбранном пространстве гипотез какую-либо функцию, аппроксимирующую истинную функцию полезности достаточно хорошо. Как и во всем научном направлении индуктивного обучения, необходимо найти компромисс между размером пространства гипотез и потребностью во времени для определения с помощью обучения требуемой функции. С увеличением пространства гипотез растет вероятность того, что может быть найдена хорошая аппроксимация, но это означает, что сходимость также, скорее всего, будет достигаться более медленно. Начнем с простейшего случая, в котором предусматривается непосредственная оценка полезности (см. раздел 21.2). При использовании функциональной аппроксимации определение такой оценки представляет собой пример контролируемого обучения. Например, предположим, что полезности для мира 4x3 представлены с использованием простой линейной функции. Характеристиками квадратов являются их координаты χ и у, поэтому получим следующее соотношение: 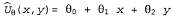 (21.9) (21.9)
|