|
По-видимому, к числу моделей на основе байесовской сети, которые наиболее широко используются в машинном обучении, относятся наивные байесовские модели. В таких моделях переменная "класса" С (значение которой должно быть предсказано) задана в корневом узле, а переменные "атрибутов" заданы в листовых узлах. Такие модели называются "наивными", поскольку в них предполагается, что атрибуты являются условно независимыми друг от друга, если определен рассматриваемый класс (модель, приведенная на рис. 20.2, б, представляет собой наивную байесовскую модель только с одним атрибутом). При условии, что переменные являются булевыми, рассматриваемые параметры принимают такой вид: заданы в листовых узлах. Такие модели называются "наивными", поскольку в них предполагается, что атрибуты являются условно независимыми друг от друга, если определен рассматриваемый класс (модель, приведенная на рис. 20.2, б, представляет собой наивную байесовскую модель только с одним атрибутом). При условии, что переменные являются булевыми, рассматриваемые параметры принимают такой вид: 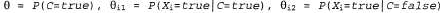
Значения параметров с максимальным правдоподобием можно найти с помощью точно такого же способа, который применялся в сети на рис. 20.2, б. Сразу после обучения данной модели с помощью такого способа она может использоваться для классификации новых примеров, в которых переменная класса С является ненаблюдаемой. При наличии значений наблюдаемых атрибутов вероятность каждого класса определяется следующим соотношением: вероятность каждого класса определяется следующим соотношением:  Детерминистическое предсказание может быть получено путем выбора наиболее вероятного класса. На рис. 20.3 показана кривая обучения для этого метода, соответствующая примеру его применения к задаче с рестораном, описанной в главе 18. Обучение с помощью этого метода происходит довольно успешно, но не так хорошо, как при обучении деревьев решений; следует полагать, это связано с тем, что истинная гипотеза (представляющая собой дерево решений) не является точно предста-вимой с помощью наивной байесовской модели. Как оказалось, метод наивного байесовского обучения действует удивительно успешно в самых разнообразных приложениях, а его усиленная версия (упр. 20.5) является одним из наиболее эффективных алгоритмов обучения общего назначения. Метод наивного байесовского обучения хорошо масштабируется на очень большие задачи: при наличии n булевых атрибутов имеется только 2п+1 параметров и для обнаружения наивной байесовской гипотезы с максимальным правдоподобием, hML, не требуется поиск. Наконец, метод наивного байесовского обучения не сталкивается с затруднениями при обработке зашумленных данных и может предоставить вероятностные предсказания, когда это необходимо.  Рис. 20.3. Кривая обучения для случая применения метода наивного байесовского обучения к задаче с рестораном из главы 18; для сравнения показана кривая обучения для случая применения метода обучения дерева решений
|