|
Страница 2 из 5 Самые ранние системы информационного поиска действовали на основе булевой модели ключевых слов. Каждое слово в коллекции документов рассматривалось как булева характеристика, которая является истинной применительно к данному документу, если соответствующее слово встречается в документе, и ложной в противном случае. Поэтому характеристика "поиск" является истинной для текущей главы, но ложной для главы 15. В таком случае язык запросов представляет собой язык булевых выражений, заданных на характеристиках. Документ считается релевантным, только если соответствующее выражение принимает истинное значение. Например, запрос [информация AND поиск] принимает истинное значение для текущей главы и ложное для главы 15. Преимуществом такой модели является то, что ее несложно описать и реализовать. Но она имеет некоторые недостатки. Во-первых, степень релевантности документа измеряется одним битом, поэтому отсутствуют руководящие данные, на основании которых можно было бы упорядочить релевантные документы для презентации. Во-вторых, булевы выражения могут оказаться непривычными для пользователей, не являющихся программистами или логиками. В-третьих, задача формулировки подходящего запроса может оказаться сложной даже для квалифицированного пользователя. Предположим, что предпринимается попытка выполнить запрос [информация AND поиск AND модели AND оптимизация], что приводит к получению пустого результирующего набора. После этого осуществляется попытка выполнить запрос [информация OR поиск OR модели OR оптимизация], но если он возвращает слишком большой объем результатов, то нелегко определить, какую попытку следует предпринять после этого. В большинстве систем информационного поиска используются модели, основанные на статистических сведениях о количестве слов (а иногда и другие характеристики низкого уровня). В этой главе будет описана вероятностная инфраструктура, которая хорошо согласуется с описанными ранее языковыми моделями. Основная идея состоит в том, что после формулировки некоторого запроса требуется найти документы, которые с наибольшей вероятностью будут релевантными по отношению к нему. Иными словами, необходимо вычислить следующее значение вероятности: 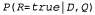
где D— документ; Q— запрос; R — булева случайная переменная, обозначающая релевантность. После получения этого значения можно применить принцип ранжирования вероятностей, который указывает, что если результирующий набор должен быть представлен в виде упорядоченного списка, это следует сделать в порядке уменьшения вероятности релевантности.
|