|
Страница 4 из 4 Этот диаграммный синтаксический анализатор характеризуется только полиномиальными затратами времени и пространства. Он требует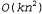 пространства для хранения ребер, где n — количество слов в предложении, а к — константа, которая зависит от грамматики. Если алгоритм не может продолжать дальнейшее формирование ребер, он останавливается, поэтому известно, что работа данного алгоритма всегда завершается (даже при наличии леворекурсивных правил). В действительности он требует времени пространства для хранения ребер, где n — количество слов в предложении, а к — константа, которая зависит от грамматики. Если алгоритм не может продолжать дальнейшее формирование ребер, он останавливается, поэтому известно, что работа данного алгоритма всегда завершается (даже при наличии леворекурсивных правил). В действительности он требует времени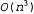 даже в наихудшем случае, а это — самые лучшие показатели, которые могут быть достигнуты при использовании контекстно-свободных грамматик. Узким местом алгоритма Chart-Parse является процедура Extender, которая должна предпринять попытку продления каждого из О(п) неполных ребер, оканчивающихся в позиции j, с помощью каждого из 0{п) полных ребер, начинающихся с позиции j, для каждого из n+1 различных значений j. Перемножая эти числа, получаем значение даже в наихудшем случае, а это — самые лучшие показатели, которые могут быть достигнуты при использовании контекстно-свободных грамматик. Узким местом алгоритма Chart-Parse является процедура Extender, которая должна предпринять попытку продления каждого из О(п) неполных ребер, оканчивающихся в позиции j, с помощью каждого из 0{п) полных ребер, начинающихся с позиции j, для каждого из n+1 различных значений j. Перемножая эти числа, получаем значение . Полученные результаты довольно парадоксальны — как может алгоритм с затратами времени . Полученные результаты довольно парадоксальны — как может алгоритм с затратами времени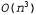 возвратить ответ, в котором может содержаться экспоненциальное количество деревьев синтаксического анализа? Рассмотрим один пример; следующее предложение: Fall leaves fall and spring leaves spring является неоднозначным, поскольку в нем каждое слово (кроме "and") может быть либо существительным, либо глаголом, a "fall" и "spring" могут быть также прилагательными. В целом этому предложению могут соответствовать четыре приведенных ниже варианта5 синтаксического анализа. возвратить ответ, в котором может содержаться экспоненциальное количество деревьев синтаксического анализа? Рассмотрим один пример; следующее предложение: Fall leaves fall and spring leaves spring является неоднозначным, поскольку в нем каждое слово (кроме "and") может быть либо существительным, либо глаголом, a "fall" и "spring" могут быть также прилагательными. В целом этому предложению могут соответствовать четыре приведенных ниже варианта5 синтаксического анализа. [S: [S: [NP: Fall leaves] fall] and [S: [NP: spring leaves] spring] [S: [S: [NP: Fall leaves] fall] and [S: spring [VP: leaves spring]] [S: [S: Fall [VP: leaves fall]] and [S: [NP: spring leaves] spring] [S: [S: Fall [VP: leaves fall]] and [S: spring [VP: leaves spring]] Если имеется п неоднозначных сочетающихся друг с другом фрагментов предложения, то может быть предусмотрено способа выбора вариантов синтаксического анализа для этих фрагментов предложения. Как избежать экспоненциального роста затрат времени на обработку при использовании данного алгоритма диаграммного синтаксического анализатора? По сути на этот вопрос можно дать два ответа. Первый ответ состоит в том, что сам алгоритм Chart-Parse фактически представляет собой не синтаксический анализатор, а распознаватель. Если в диаграмме имеется полное ребро в форме способа выбора вариантов синтаксического анализа для этих фрагментов предложения. Как избежать экспоненциального роста затрат времени на обработку при использовании данного алгоритма диаграммного синтаксического анализатора? По сути на этот вопрос можно дать два ответа. Первый ответ состоит в том, что сам алгоритм Chart-Parse фактически представляет собой не синтаксический анализатор, а распознаватель. Если в диаграмме имеется полное ребро в форме , это означает, что какое-то словосочетание S распознано. Восстановление дерева синтаксического анализа из информации, заданной в этом ребре, не рассматривается как часть функций алгоритма Chart-Parse, но может быть выполнено с его помощью. Обратите внимание на то, что в последней операции процедуры Extender строка α формируется как список ребер , это означает, что какое-то словосочетание S распознано. Восстановление дерева синтаксического анализа из информации, заданной в этом ребре, не рассматривается как часть функций алгоритма Chart-Parse, но может быть выполнено с его помощью. Обратите внимание на то, что в последней операции процедуры Extender строка α формируется как список ребер 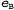 , а не просто как список имен категорий. Поэтому, чтобы преобразовать ребро в дерево синтаксического анализа, достаточно выполнить рекурсивный просмотр составляющих ребер, преобразовав каждое ребро , а не просто как список имен категорий. Поэтому, чтобы преобразовать ребро в дерево синтаксического анализа, достаточно выполнить рекурсивный просмотр составляющих ребер, преобразовав каждое ребро  в дерево [X: а]. Такой процесс является несложным, но позволяет получить только одно дерево синтаксического анализа. в дерево [X: а]. Такой процесс является несложным, но позволяет получить только одно дерево синтаксического анализа. Второй ответ состоит в том, что если требуются все возможные варианты синтаксического анализа, то придется глубже разобраться в этой диаграмме. Во время преобразования ребра в дерево [X: а] можно будет проверить, есть ли какие-либо другие ребра в форме в дерево [X: а] можно будет проверить, есть ли какие-либо другие ребра в форме . Если они имеются, то эти ребра должны сформировать дополнительные варианты синтаксического анализа. Определив все эти варианты, необходимо будет продумать вопрос, что с ними делать. Можно просто перечислить все варианты, а это означает, что указанный выше парадокс будет разрешен и потребуется экспоненциальное количество времени для составления списка всех вариантов синтаксического анализа. Еще один подход может состоять в том, чтобы еще немного продолжить эту работу и представить варианты синтаксического анализа в виде структуры, называемой ^ упакованным лесом, который выглядит примерно так: . Если они имеются, то эти ребра должны сформировать дополнительные варианты синтаксического анализа. Определив все эти варианты, необходимо будет продумать вопрос, что с ними делать. Можно просто перечислить все варианты, а это означает, что указанный выше парадокс будет разрешен и потребуется экспоненциальное количество времени для составления списка всех вариантов синтаксического анализа. Еще один подход может состоять в том, чтобы еще немного продолжить эту работу и представить варианты синтаксического анализа в виде структуры, называемой ^ упакованным лесом, который выглядит примерно так: 
Идея этого способа представления состоит в том, что каждый узел дерева синтаксического анализа может быть либо обычным узлом дерева, либо множеством узлов дерева. Это позволяет возвратить из программы некоторое представление экспоненциального количества вариантов синтаксического анализа за счет полиномиальных затрат пространства и времени. Безусловно, если п=2, то разницы между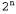 и2л нет, но при больших значениях η такое представление обеспечивает значительную экономию. К сожалению, этот простой подход на основе упакованного леса не позволяет учесть все 0{п\) вариантов неоднозначности, касающиеся того, как могут быть связаны между собой различные составляющие. Максвелл и Каплан [1002] показали, что некоторый более сложный способ представления, основанный на принципах систем поддержки истинности, позволяет упаковывать деревья еще плотнее. и2л нет, но при больших значениях η такое представление обеспечивает значительную экономию. К сожалению, этот простой подход на основе упакованного леса не позволяет учесть все 0{п\) вариантов неоднозначности, касающиеся того, как могут быть связаны между собой различные составляющие. Максвелл и Каплан [1002] показали, что некоторый более сложный способ представления, основанный на принципах систем поддержки истинности, позволяет упаковывать деревья еще плотнее.
<< В начало < Предыдущая 1 2 3 4 Следующая > В конец >>
|